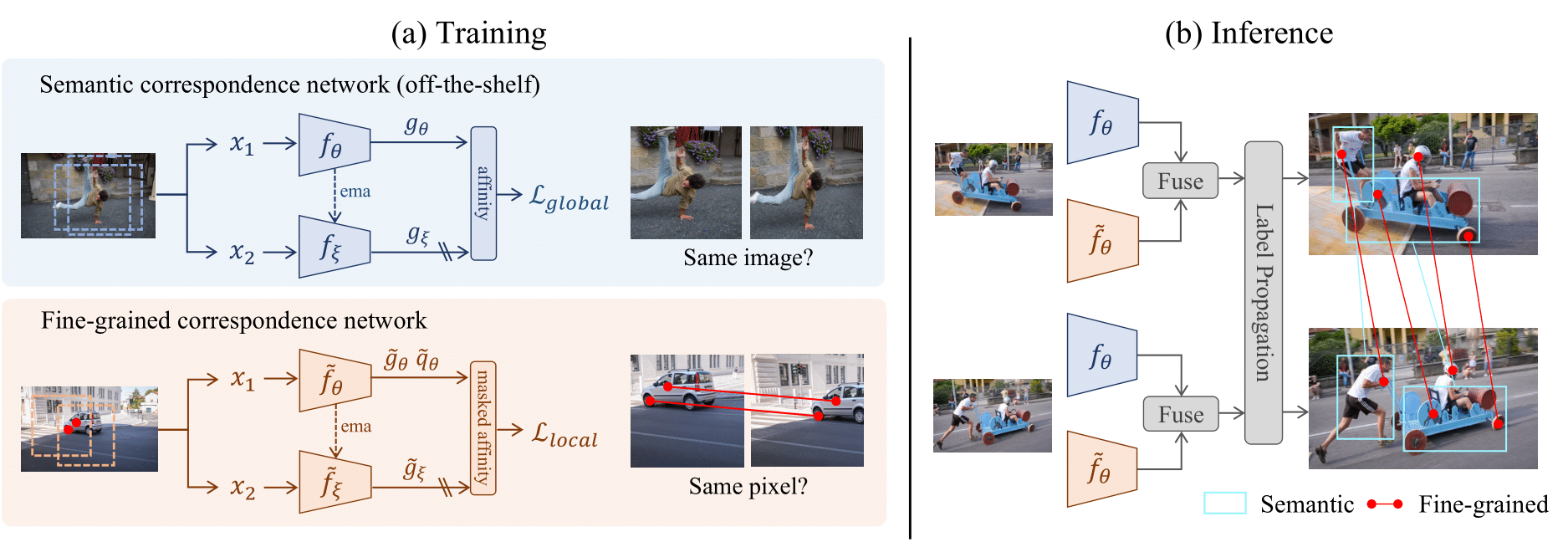
We learn high-level semantic representations and low-level fine-grained representations at training time. At test-time, we fuse these two complementary representations and perform label propagation without further finetuning.
Establishing visual correspondence across images is a challenging and essential task. Recently, an influx of self-supervised methods have been proposed to better learn representations for visual correspondence. However, we find that these methods often fail to leverage semantic information and over-rely on the matching of low-level features. In contrast, human vision is capable of distinguishing between distinct objects as a pretext to tracking. Inspired by this paradigm, we propose to learn semantic-aware fine-grained correspondence. Firstly, we demonstrate that semantic correspondence is implicitly available through a rich set of image-level self-supervised methods. We further design a pixel-level self-supervised learning objective which specifically targets fine-grained correspondence. For downstream tasks, we fuse these two kinds of complementary correspondence representations together, demonstrating that they boost performance synergistically. Our method surpasses previous state-of-the-art self-supervised methods using convolutional networks on a variety of visual correspondence tasks, including video object segmentation, human pose tracking, and human part tracking.